Поиск и индексирование в Lingvo
Эта тема имеет непосредственное отношение к пониманию действия тэгов поисковой обработки [ex], [com], [trn] и [!trs].
Поскольку язык DSL разрабатывался специалистами ABBYY специально для использования в Lingvo, его устройство тесно связано с особенностями работы этой программы. Одной из таких особенностей является организация поиска слов по тексту словарей и связанный с этим процесс индексирования.
Одним из основных и бесспорных преимуществ электронных словарей в сравнении с бумажными является возможность быстрого (а лучше мгновенного) поиска по содержимому. Отметим, что речь при этом идёт как правило не об одном словаре, а о десятках, иногда даже сотнях. И скорость при осуществлении данной задачи является фактором ключевым, хотя и не единственным. Рассмотрим, как этот процесс организован в Lingvo.
При подключении к Lingvo нового словаря программа автоматически запускает процесс индексирования, во время которого происходит анализ содержимого словаря и составляется индекс — полный компактный перечень всех входящих в словарь слов. Построение индекса требует времени, но выполняется оно единожды. При последующих поисковых запросах слово ищется уже не в словаре, а в индексе, благодаря чему и достигается высокая скорость поиска.
Индекс записывается в файлы *.trs и располагается в пользовательской папке ..\Application Data\Local\ABBYY\Lingvo. При добавлении каждого нового словаря индекс пополняется и, соответственно, растёт его размер и кол-во файлов. Очевидно, что для того, чтобы размер не увеличивался напрасно, при создании индекса в него должны включаться только полезные данные (а бесполезные исключаться). Регулирование этого процесса предусмотрено на уровне DSL.
Зоны текста, которые обрабатываются или игнорируются Lingvo при составлении индекса, размечаются в DSL при помощи тэгов. Т.о. по отношению к индексу тэги могут быть включающими и исключающими.
Исключающими из индекса являются тэги: прежде всего [!trs], затем [p], [ref], <<…>>, [url], [s], [video]. Из перечисленных только у первого [!trs] функция исключения из индекса — главная и единственная, у остальных она не единственна и побочна.
Включающими в индекс являются тэги: [trn], [ex] и [com]. Кроме того в индекс в обязательном порядке попадают все словарные заголовки.
Механизм влияния включающих тэгов на операцию индексирования рассмотрим на простом примере. Создадим тестовый DSL словарик из одной карточки:

Мы видим, что часть текста находится в зоне действия включающих тэгов [trn], [ex] и [com] — этот текст должен быть включен в состав индекса. Один фрагмент находится за пределами включающего [trn], а другой обрамлен исключающим [!trs] — этот текст в индекс попасть не должен. Теперь проверим так ли это на практике. Компилируем словарик, подключаем его к Lingvo и выполняем поисковый запрос по слову «гвоздь».
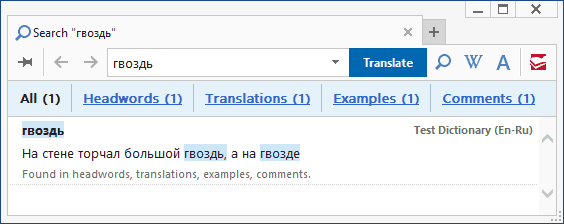
Как видим, результаты поиска распределены по категориям: заголовки, переводы, примеры и комментарии. Именно на эти категории были нацелены наши включающие тэги: [trn] — для переводов, [ex] — для примеров, [com] — для комментариев, а заголовки проиндексировались без дополнительной разметки. Искомое слово найдено во всех четырёх категориях. Сравниваем с исходным DSL: действительно, «гвоздь» встречается как в области действия всех включающих тэгов, так и в заголовках. Теперь поищем слово «фуражка».
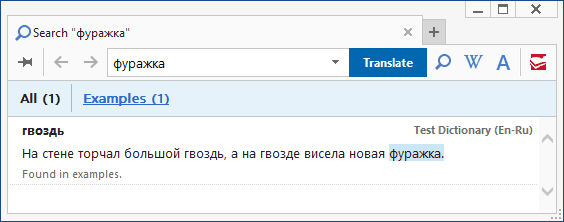
Как видим, слово нашлось только в категории примеров. Всё правильно: в заголовках его нет, в зону переводов [trn] оно не попало, а из зоны комментариев [com] мы его исключили при помощи [!trs].
Итак, пример наглядно продемонстрировал нам следующее:
- В состав индекса включаются заголовки и текст, находящийся в зоне действия включающих тэгов.
- Каждый из включающих тэгов образует отдельную категорию в индексе.
- В состав индекса не попадает текст, находящийся за пределами зоны действия включающих тэгов, а также текст, занесённый в зону действия исключающих тэгов.
- Механизм поиска находит только те слова, которые попали в состав индекса.
При помощи аккуратной разметки мы добились того, что в индекс вошли только полезные данные, следовательно его объём стал максимально экономичным, а состав — максимально эффективным. Однако такая подготовка DSL требует от составителя специальных технических навыков, особенно при обработке словарей большого объёма. На сотнях или тысячах строк необходимо правильно расставить тэги и ничего не упустить, иначе неразмеченный текст станет недоступным для поиска в Lingvo. Не каждому пользователю по силам подобная задача. Для таких случаев в Lingvo предусмотрен другой способ разметки — автоматический. Как это происходит, мы рассмотрим на другом примере.
Создадим тестовый словарик, аналогичный предыдущему по строению, но, для наглядности, на английском языке:

Теперь отконвертируем его в формат LSD при помощи DSL Compiler, предварительно включив в компиляторе опцию Create dictionary ready for indexing. Полученный LSD откроем в hex-редакторе и посмотрим, что внутри.
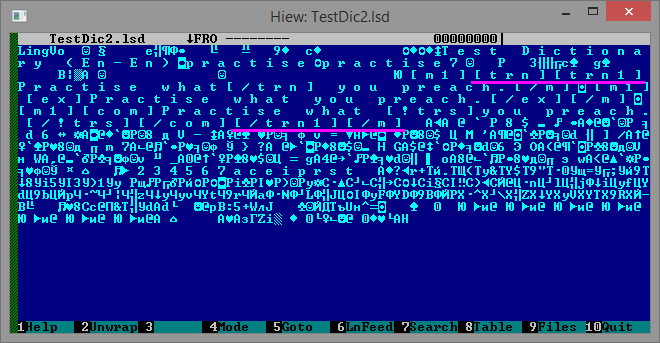
Как видим, в начале и в конце статьи появились дескрипторы нового тэга, которого не было в исходном DSL (на снимке они подчёркнуты пурпурными линиями). Его имя [trn1] почти совпадает с именем уже известного нам [trn], отличаясь от него всего единицей. В чём же их существенное сходство и различие?
Недокументированный тэг [trn1] подобно своему родственнику [trn] причисляет текст к поисковой категории Translations. Отличается же он тем, что предназначен только для автоматической разметки, т.е. его нельзя поместить, как [trn], в текст DSL самостоятельно — компилятор опротестует подобную попытку. Разница же в имени сделана для того, чтобы родственники не конфликтовали друг с другом. Мы уже знаем о запрете DSL размещать одинаковые тэги в зоне действия друг друга. Если бы мы в своём DSL расставили [trn] вручную, а затем во время компилирования включили бы ещё автоматическую разметку, наши [trn] попали бы в зону действия [trn] расставленных компилятором, и это привело бы к невозможности создать полноценный LSD. Во избежание подобных конфликтов тэгу автоматической разметки присвоено отличающееся имя — [trn1].
Итак, суммируем полученные знания и наблюдения:
- При автоматической разметке тэги индексирования помещаются в начало и конец каждой словарной статьи. Т.о. весь текст словаря становится доступен для полнотекстового поиска.
- Автоматическая разметка причисляет текст к поисковой категории Translations.
- Современная автоматическая разметка, выполняемая в Lingvo x6 (и последних версиях x5), не порождает конфликтов с другими тэгами DSL.
- Для создания автоматической разметки используется недокументированный тэг [trn1]. Этот тэг не может быть использован никаким иным, кроме автоматики, способом.
- Автоматическая разметка менее экономична и аккуратна по сравнению с разметкой вручную, но зато не требует от составителя словаря специальных технических знаний и навыков.